
Matt Juden shares learning from working with evaluation teams to apply new approaches to eliciting prior beliefs over relationships in a causal model.
This blog post summarises our approach to working with two evaluation teams to formally encode their theories of how the interventions they were trialling were supposed to work. Our work involved developing a completely novel approach to eliciting prior beliefs over relationships in a causal model, which only came together after many false starts and dead ends. We hope that the work we have done will enable other researchers to elicit prior beliefs over much more complex models than was previously possible.
In this blog post we look at some of the key lessons learned about the theory behind the partner interventions. In particular, we reflect on the fact that for both sets of experts, their implicit priors as expressed through the effects they predict for hypothetical beneficiaries diverged from their explicit priors when asked about the structure of the causal model. We are extremely grateful to both teams for generously giving their time to partner with us and being participants in an experimental, time-consuming approach of uncertain utility.
The partner teams we worked with were made up of academics and implementation partners who had designed, implemented and were studying two complex social interventions. The first partner team was studying a nutrition-sensitive agriculture intervention in India called Upscaling Participatory Action and Videos for Agriculture and Nutrition (UPAVAN), while the second was studying a disability-inclusive version of a poverty graduation intervention in Uganda, called Disability Inclusion Graduation (DIG).
Formalising partners’ theories
We took a two-stage approach to formalising our partner team’s theories about how the intervention was supposed to work. First, we had to discover the structure of their mental model(s) of intervention causation. This meant starting from theory of change diagrams and supporting text about intervention theory and working together to create a directed acyclic graph (DAG). We talk about this process in relation to the UPAVAN intervention in our previous blog post.
Once we had a DAG from both intervention teams, we had the structure of causal relations between the elements in our exerts’ theory expressed as a series of labelled boxes (or ‘nodes’) connected by arrows. These elements were all defined such that they represented true or false statements — i.e., were binary. We also allowed for ternary or quaternary nodes if necessary, though only two ternary nodes were needed for one of our partner teams’ DAGs.
We also asked the experts to tell us their assumptions about the fundamental nature of the arrows in the DAG. We asked if these arrows represented non-monotonic causal effects. That is, did they expect any of the arrows from an upstream ‘parent’ node to represent causation that could cause negative as well as positive changes in the value of the downstream ‘child’ node? Generally, our experts’ theories were about monotonic causation, where any effects would all have the same sign – these were ‘positive’ theories of change. Where a child node had more than one parent, we asked whether the effects of those parents were expected to be interacting or non-interacting.
We then had the skeletal structure of a causal model. However, we did not have any information about the expected strength of relationships in the model. We really needed the prior beliefs held by the experts about the strength of relationships in the model to have an informative prior model of how the intervention was supposed to work.
Collecting priors and updating the causal model
Finding a way to collect these priors and update the causal model in software was challenging. The software we were using, CausalQueries, is powerful but was designed for fairly simple models. Prior beliefs can be manually entered into the model, but these must be expressed as relative shares of something called ‘nodal types.’ It is outside the scope of this blog to explain nodal types in detail, but in the simplest terms, a nodal type is one possible way that a child node could react to the possible values of its parents. Even for binary nodes caused by k binary parents, there are a lot of nodal types: 2^2^k in fact. This means a binary node with two parents has 16 nodal types, whereas one with four parents has 65,536. Assuming that the parents’ causal effects do not interact with each other reduces this number a bit. However, this assumption is not always defensible and it is still not enough to allow for a number of parameters that could feasibly be elicited from participants.
After trying several alternative approaches, we eventually found a practicable method for creating a prior model in CausalQueries. We did this by serving participants with contingency tables for each child node with rows for all the possible parent node value combinations and a column asking for point estimates of the probability of the child node taking the value 1. The intuition behind using contingency tables to elicit priors was that even when there are unmanageably many nodal types for a given child node, there is a much smaller and somewhat manageable number of possible combinations of binary parent node values. If we ask participants for an estimate of the probability of the child node taking the value 1 given each combination of parent nodes, those answers imply much richer information about the strength, direction and interactions of causal effects of the parent nodes. We can use these point estimates combined with information about the experts’ confidence in their answers to infer the experts’ beliefs about the distribution of true causal effects for each combination of parent node values. We can use those distributions to generate data on which we can update the Bayesian model in CausalQueries to create the prior model that we need.
For example, here is one of the contingency tables from the training exercise that proceeded our prior elicitation exercise:
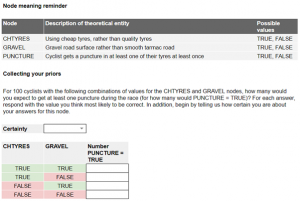
We asked participants to fill in point estimates for the probability of the child node taking the value ‘true’ for each possible combination of parent node values and asked for a level of certainty about the answers in the whole table. Asking about the level of certainty at the level of the table rather than per answer was a simplification that we adopted to reduce the time needed to answer after piloting suggested that level of certainty varied much more between nodes than within the questions for a given node. Read-only public copies of the prior elicitation tools we used are available at these links:
UPAVAN prior elicitation tool public copy
DIG prior elicitation tool public copy
We developed this novel method because prior elicitation strategies that have been well-documented in the literature are suitable for eliciting single parameters or small numbers of parameters and involve time-consuming tasks such as drawing distributions or allocating counters to a scale to create histograms. With our method, we were able to elicit up to 114 distributions from participants in approximately 45 minutes of participant time.
We were successfully able to use this method to elicit priors from our partner team experts, although not without some difficulty on the respondents’ part. We had to offer support to experts beyond our training exercise in order to help them to understand the exercise. The experts reported understanding the tool and being confident in their answers, but the time engagement necessary for participants led to some attrition in our samples.
Once we had elicited experts’ priors in this way, we were able to run some tests to assess whether the implicit priors over causal effects elicited in this way were consistent with experts’ explicit priors elicited during the DAG elicitation process. Monotonicity assumptions were generally consistent between explicit and implicit priors, but interactions in causal effects were not in some interesting ways. In the UPAVAN case, the causal effects implied by answers to the prior elicitation exercise were not interactive for the nodes where this had been said to be necessary during the prior elicitation process, though there was some evidence of interactive effects for other nodes. In the DIG case, a key rationale for the use of many intervention components for this project was that these components are said to have interactive effects. However, the prior beliefs elicited from experts during the prior elicitation process suggested no expectation of interactive effects. It will be very interesting, in our next paper, to explore what data from the trials implies about these effects.
We hope that other teams considering Bayesian causal models will be able to learn from our approach and might be able to adapt the tools that we have developed. We have shown that our method is practicable, though it is challenging even for motivated and technically trained participants. It is possible that a similar tool could be made more user-friendly through improved user experience design, perhaps by developing a more comprehensive training exercise and by using input techniques that involved graphical elements such as moving sliders rather than inputting numbers. We would welcome the opportunity to work with others to trial such improvements.